Abstract (Kor)
본 연구는 단안(monocular) 영상으로부터의 3D 인체 자세 추정에서 빈번한 가림(occlusion)과 단안 모호성(ambiguity)으로 인해 발생하는 불안정하고 시간적으로 일관되지 않은 예측 문제를 해결하고자 한다. 기존의 회귀(regression) 기반 기법은 가림 상황에서 평균으로의 회귀(regression-to-the-mean) 현상으로 인해 부정확한 자세를 출력하며, 최근 제안된 PCT와 같은 토큰 기반 기법은 자세 공간을 이산화하여 구조적 타당성을 강화하지만, 프레임 단위(frame-wise)로 동작하기 때문에 시간적 연속성을 반영하지 못하고 고주파 진동(jitter)을 야기한다.
이를 해결하기 위해 본 연구는 Spatio-Temporal Tokenization Framework를 제안한다. 제안하는 프레임워크는 이산 표현(discrete representation)의 구조적 강건성과 시간 모델링(temporal modeling)의 부드러움을 결합하여, 인체 운동을 연속적인 관절 좌표 시퀀스가 아닌 이산 잠재 상태(discrete latent states)의 궤적으로 표현한다. 제안 기법은 다음의 세 가지 핵심 구성 요소로 이루어진다.
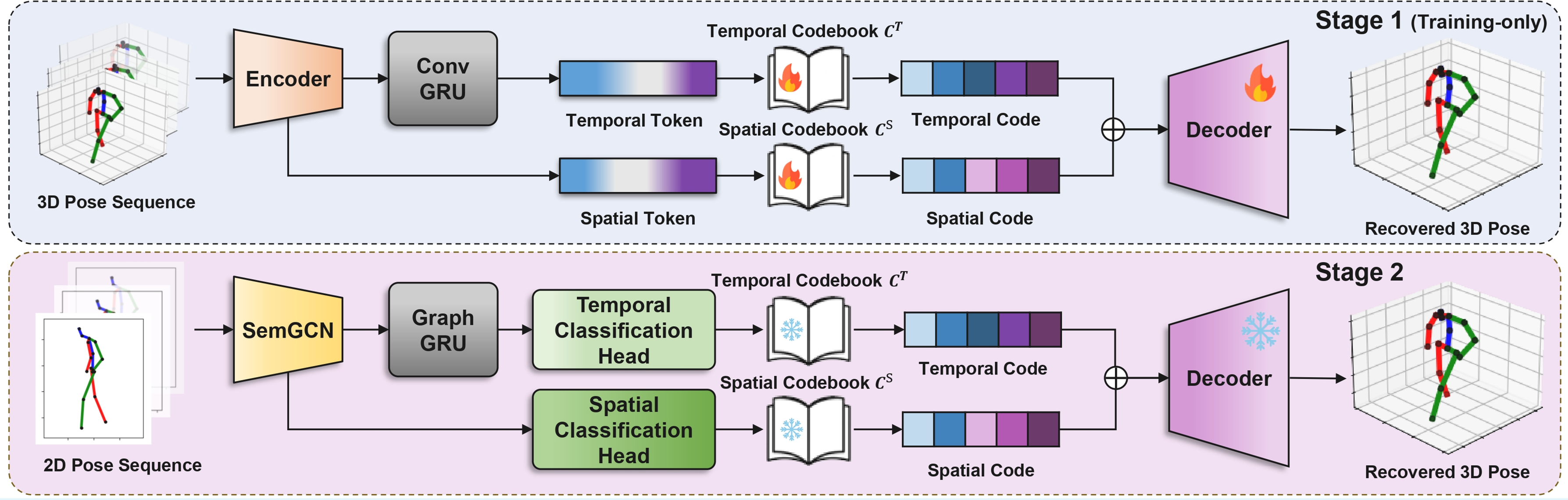
1) Dual-Codebook Pose Tokenizer (Stage 1)
3D 자세 시퀀스를 MLP-Mixer 인코더와 ConvGRU를 통해 인스턴스 단위의 자세 기하(spatial token)와 시퀀스 단위의 운동 동역학(temporal token)으로 분리(disentangle)한다. 이렇게 분리된 두 표현은 각각 Spatial Codebook ($C^S$) 과 Temporal Codebook ($C^T$) 에 매핑되어, 골격의 구조적 사전 지식(skeletal prior)과 시간적으로 타당한 운동 사전 지식(motion prior)을 독립적으로 모델링한다.
2) SemGCN–GraphGRU Token Classifier (Stage 2)
2D 자세 시퀀스로부터 사전 학습된 코드북의 최적 인덱스를 예측하는 토큰 분류기를 학습한다. SemGCN은 학습 가능한 인접 행렬(adjacency matrix)을 통해 프레임 내 관절 간의 국소적·비국소적 공간 의존성을 모델링하며, GraphGRU는 프레임 간 시간적 동역학을 포착한다. 학습 시에는 soft quantization을 통해 3D 재구성 오차를 end-to-end로 최소화하고, 추론 시에는 hard quantization을 적용하여 가장 확률이 높은 토큰 인덱스를 선택한다.
3) Masked Joint Modeling (MJM) 전략
학습 단계에서 일부 관절을 무작위로 마스킹하여 모델이 관절 간 의존성과 시간적 흐름에 강하게 의존하도록 유도함으로써, 가림 상황에서도 구조적으로 타당한 자세를 복원할 수 있도록 한다.
이를 통해 제안 프레임워크는 가림 부위를 구조적으로 타당한 자세 사전 지식으로 복원하면서, 동시에 시간적으로 일관된 운동 궤적을 유지할 수 있다. Human3.6M 벤치마크에서 광범위한 실험을 수행한 결과, 단일 프레임 baseline인 PCT 대비 10.43%의 상대 성능 향상을 달성하였으며, 단 20프레임의 짧은 수용 영역(receptive field)만을 사용하면서도 장시퀀스 기반의 최신(SOTA) 기법들과 견줄 만한 성능을 보였다. 특히 머리 관절의 속도·가속도 프로파일 분석에서, 제안 기법은 baseline 대비 고주파 진동을 현저히 감소시켜 부드럽고 물리적으로 타당한 3D 자세 시퀀스를 생성함을 확인하였다.
Abstract (Eng)
This study addresses the inherent challenges of monocular 3D human pose estimation, where frequent occlusions and depth ambiguities lead to unstable and temporally inconsistent predictions. Conventional regression-based methods suffer from regression-to-the-mean under occlusion, while recent token-based approaches such as PCT enforce structural validity through discrete pose representations but operate strictly in a frame-wise manner, resulting in high-frequency jitter and temporal inconsistency.
To overcome these limitations, we propose a Spatio-Temporal Tokenization Framework that unifies the structural robustness of discrete representations with the smoothness of temporal modeling. By representing human motion as a trajectory of discrete latent states rather than a sequence of continuous joint coordinates, the proposed framework provides a more natural representation of human movement. The framework consists of three key components.
1) Dual-Codebook Pose Tokenizer (Stage 1)
A 3D pose sequence is disentangled into instantaneous pose geometry (spatial tokens) and sequence-level motion dynamics (temporal tokens) using an MLP-Mixer encoder and a ConvGRU. These two representations are then mapped into separate discrete codebooks—a Spatial Codebook ($C^S$) and a Temporal Codebook ($C^T$)—via vector quantization, enabling explicit and independent modeling of skeletal structural priors and temporally feasible motion priors.
2) SemGCN–GraphGRU Token Classifier (Stage 2)
A token classifier is trained to predict the optimal codebook indices from 2D pose sequences. SemGCN captures both local skeletal constraints and non-local joint correlations within each frame through a learnable adjacency matrix, while GraphGRU models temporal dynamics across frames. During training, soft quantization enables end-to-end minimization of the 3D reconstruction error, whereas hard quantization is applied during inference to select the most probable token indices.
3) Masked Joint Modeling (MJM) Strategy
Random joint masking forces the model to rely on inter-joint dependencies and temporal flow, enabling robust reconstruction of occluded body parts while preserving structurally valid pose priors.
By leveraging structurally valid pose priors together with temporally consistent motion representations, the proposed framework achieves robust 3D pose estimation under occlusion and motion ambiguity. Extensive experiments on the Human3.6M benchmark demonstrate that our method outperforms the single-frame baseline PCT by a margin of 5.3 mm in MPJPE, corresponding to a 10.43% relative improvement. Despite utilizing a receptive field of only 20 frames, our method achieves performance competitive with state-of-the-art long-sequence approaches. Furthermore, velocity and acceleration profile analyses on the head joint confirm that the proposed framework substantially suppresses high-frequency jitter, producing smooth and physically plausible 3D pose sequences suitable for real-world applications such as digital humans and AR.
Token perturbation experiments further validate the interpretability of the learned latent space: altering a spatial token modifies only local skeletal geometry, while perturbing a temporal token alters motion dynamics without affecting skeletal integrity. This clean disentanglement highlights the advantage of the dual-codebook design in independently controlling pose and motion, opening avenues for controllable motion editing and text-conditioned motion generation.