Abstract (Kor)
본 연구는 CLIP 기반 다중 레이블 분류에서 기존 방법들이 가지는 객체 중심 편향과 배경 정보 활용의 한계를 해결하고자 한다. 기존 CLIP 기반 접근법은 객체와 배경 간의 문맥적 관계를 충분히 반영하지 못하며, 특히 작은 객체에 대한 인식 성능이 저하되는 문제가 있다.
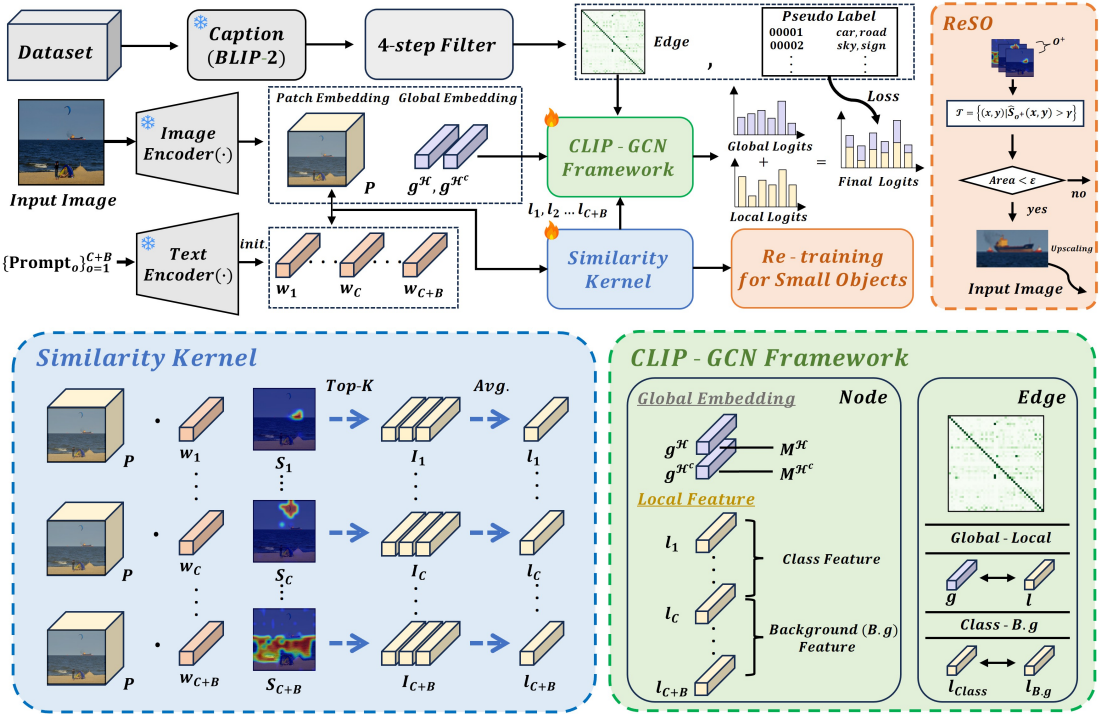
이를 해결하기 위해 Background-Aware CLIP-GCN (BAC-GCN) 프레임워크를 제안한다. BAC-GCN은 클래스와 배경 간 상호작용을 명시적으로 모델링하여 복잡한 시각적 문맥을 효과적으로 학습한다. 제안하는 방법은 다음의 세 가지 핵심 구성 요소로 이루어진다.
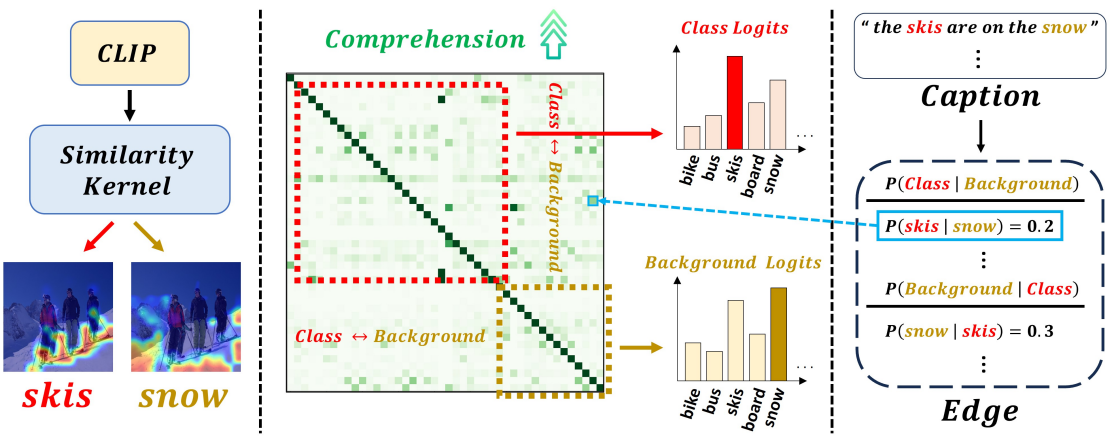
1) Similarity Kernel
클래스 및 배경(category)별로 패치 수준의 지역적(local) 특징을 추출하여, 세밀한 시각 패턴을 효과적으로 포착한다.
2) CLIP-GCN
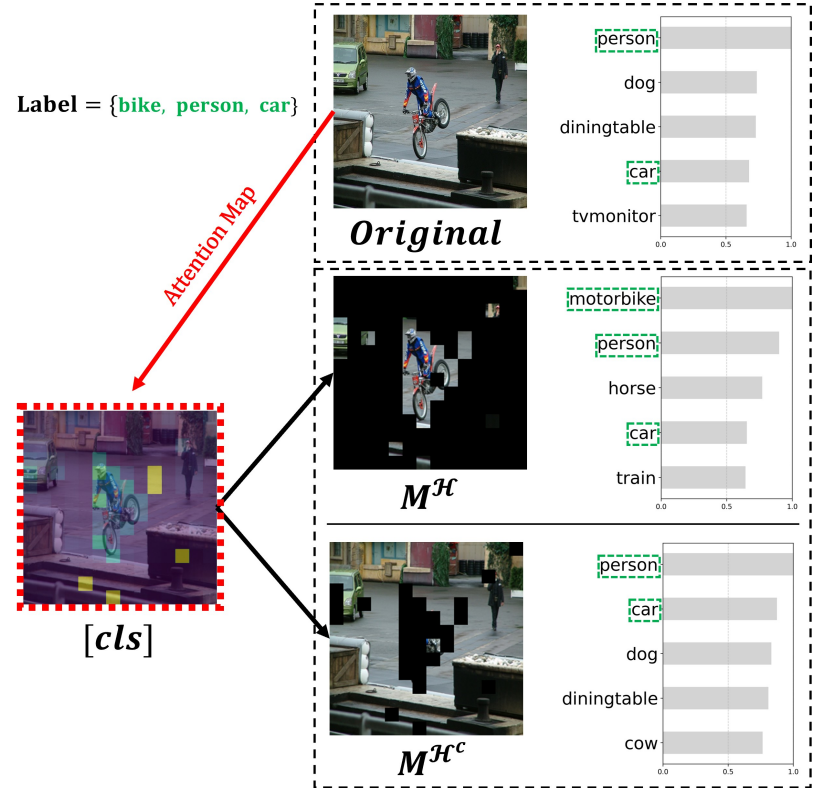
로컬–글로벌 특징과 클래스–배경 간의 관계적 의존성을 그래프 신경망을 통해 모델링하여, 풍부한 문맥 정보를 학습한다.
3) Re-Training for Small Objects (ReSO) 전략
학습이 어려운 소형 객체 및 희소 클래스에 대해 재학습을 수행함으로써, 이들의 고유한 시각적 특성 표현을 강화한다.
이를 통해 BAC-GCN은 다양한 시각적 단서와 그 관계를 종합적으로 활용하여 보다 정교한 다중 레이블 분류 결정을 가능하게 한다. 광범위한 실험을 통해 VOC07, COCO, NUS의 세 가지 대표적인 다중 레이블 벤치마크 데이터셋에서 최신(State-of-the-Art) 성능을 달성하였으며, 제안 기법의 유효성을 입증하였다.
Abstract (Eng)
This study addresses the limitations of existing CLIP-based multi-label classification approaches, which primarily rely on object-centric representations and thus struggle to capture rich contextual dependencies between objects and their surrounding scenes. Moreover, due to the inherent bias of the Vision Transformer architecture toward the most salient objects, CLIP-based models often fail to accurately recognize small or less conspicuous objects.
To address these challenges, we propose Background-Aware CLIP-GCN (BAC-GCN), a novel framework that explicitly models class–background interactions to effectively capture complex visual contexts and fine-grained visual patterns of small objects. The proposed framework consists of three key components.
1) Similarity Kernel
Extracts patch-level local features for each category, including both object classes and background, enabling effective capture of fine-grained visual patterns.
2) CLIP-GCN
Models relational dependencies between local–global features and class–background representations through a graph neural network, facilitating rich contextual representation learning.
3) Re-Training for Small Objects (ReSO) Strategy
Enhances the representations of small objects by re-training on hard-to-learn samples, allowing the model to better capture their distinctive visual characteristics.
By leveraging diverse visual cues and their contextual relationships, BAC-GCN facilitates a deeper understanding of complex visual scenes and enables more accurate multi-label classification. Extensive experiments on three benchmark datasets—VOC07, COCO, and NUS—demonstrate that BAC-GCN achieves state-of-the-art performance, validating the effectiveness of the proposed approach.