Abstract (Eng)
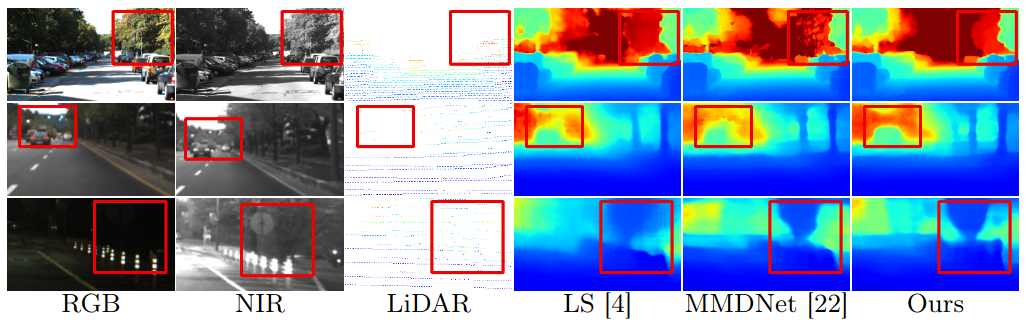
Single-modal depth estimation has shown steady improvement over the years. However, relying solely on a single imaging sensor such as RGB and near-infrared (NIR) cameras can result in unreliable and erroneous depth estimation, particularly in challenging lighting conditions such as low-light or sudden lighting change scenarios. Thereby, several approaches have leveraged multiple sensors for robust depth estimation. However, the effective fusion method that maximally utilizes multi-modal sensor information still requires further investigation. With this in mind, we propose a multi-modal cost volume fusion strategy with cross-modal attention, incorporating information from both cross-spectral and single-modality pairs. Our method initially constructs low-level cost volumes that consist of modality-specific (i.e., single modality) and modality-invariant (i.e., cross-spectral) volumes from multi-modal sensors. These cost volumes are then gradually fused using bidirectional cross-modal fusion and unidirectional LiDAR fusion to generate a multi-sensory cost volume. Furthermore, we introduce a straightforward domain gap reduction approach to learn modality-invariant features and depth refinement techniques through cost volume-guided propagation. Experimental results demonstrate that our method achieves SOTA (State-of-the-Art) performance under diverse environmental changes.
Abstract (Kor)
단일 센서를 이용한 깊이 추정은 지난 수년간 지속적으로 성능이 향상되어 왔습니다. 그러나 RGB나 근적외선 카메라와 같은 단일 영상 센서에만 의존할 경우, 저조도 환경이나 급격한 조명 변화와 같은 어려운 조건에서는 깊이 추정이 불안정해지고 오류가 발생할 수 있습니다. 이러한 한계를 극복하기 위해, 보다 강인한 깊이 추정을 목표로 여러 센서를 활용하는 다양한 접근법들이 제안되어 왔습니다. 그럼에도 불구하고, 다중 모달 센서 정보를 최대한 효과적으로 활용할 수 있는 융합 방법에 대해서는 여전히 추가적인 연구가 필요합니다. 이러한 문제의식에 기반하여, 본 논문에서는 교차 모달 어텐션을 활용한 다중 모달 비용 볼륨(cost volume) 융합 전략을 제안합니다. 제안하는 방법은 교차 분광(cross-spectral) 쌍과 단일 모달 쌍의 정보를 모두 활용합니다. 먼저, 다중 모달리티 센서로부터 센서별 비용 볼륨과 교차 분광 비용 볼륨로 구성된 저수준 비용 볼륨을 생성합니다. 이후, 양방향 교차 모달 융합과 단방향 LiDAR 융합을 통해 이들 비용 볼륨을 점진적으로 결합하여 다중 센서 비용 볼륨을 생성합니다. 또한, 모달리티 불변 특징을 학습하기 위한 간단한 도메인 갭 감소 기법과, 비용 볼륨을 활용한 전파 기반 깊이 보정 기법을 함께 도입합니다. 실험 결과, 제안하는 방법은 다양한 환경 변화 조건에서도 최신 최고 성능(State-of-the-Art)을 달성함을 확인하였습니다.
핵심 목표
다중 센서(RGB, NIR, LiDAR)의 정보를 효율적으로 결합하여, 어떠한 환경에서도 더 정확하고 안정적인 깊이 추정을 하는 것이 목적입니다. 이 연구는 기존의 단순 센서 퓨전 방식에서 한 단계 나아가, 센서 간 정보 구조를 모델 내부에서 적극적으로 상호 연관지어 이해하고 통합함으로써, 실제 현장 (자율 주행, 야간/악조건 주행)에서 훨씬 정확하고 신뢰할 수 있는 깊이 추정 성능을 제공하고자 합니다.
주요 아이디어 및 방법
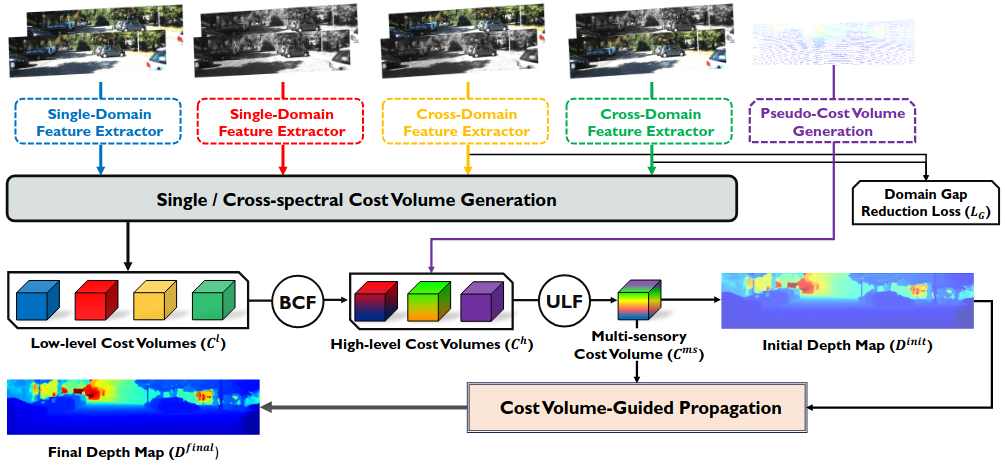
1) Cross-modal Cost Volume 생성
깊이 추정에서는 보통 두 장의 이미지 간 차이(시차)를 측정하는 구조인 cost volume을 생성합니다. 본 연구에서는 단일 모달리티 뿐만 아니라 서로 다른 모달리티 간의 교차 정보까지 생성합니다 (RGB-RGB, NIR-NIR, RGB-NIR, NIR-RGB).
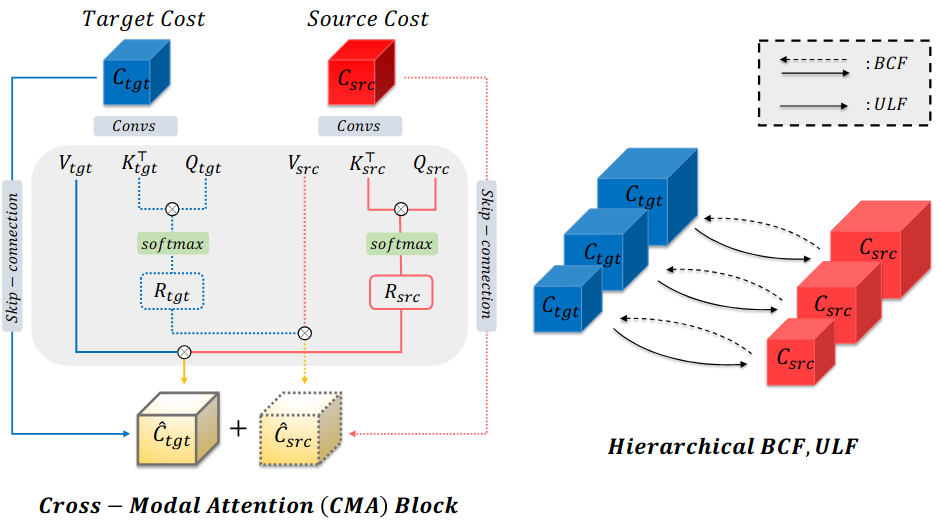
2) Cross-modal Attention 기반 융합
생성된 여러 cost volume을 단순히 섞는 것이 아니라, cross-modal attention이라는 기법으로 더 중요한 정보가 자동으로 강조되도록 합니다. 센서 간 정보가 단순 병합될 경우, 서로 중복되거나 잡음이 포함된 정보도 같이 섞일 수 있습니다. Cross-modal attention은 이런 문제를 줄이고 가장 유의미한 정보만 선택적으로 통합합니다.
3) 도메인 갭(domain gap) 감소
서로 다른 센서(RGB, NIR)은 빛의 성질이 달라서 같은 장면이라도 특징 차이가 큽니다. 이를 줄이기 위해 구조적 일관성을 유지하도록 학습하는 추가 손실 함수를 도입해 서로 다른 모달 간의 gap을 줄입니다.
4) Cost Volume-guided Propagation
초기 추정된 깊이 맵을 단순하게 예측하는 것이 아니라, cost volume 정보를 활용해 연속적으로 정보를 보완하고 refinement하는 구조를 적용합니다.