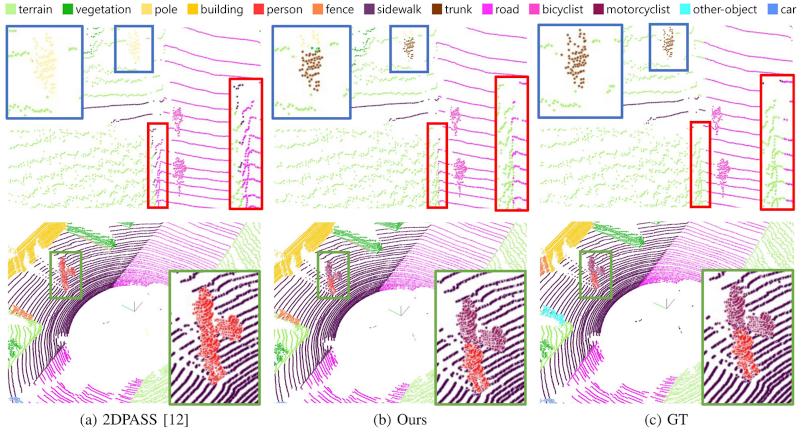
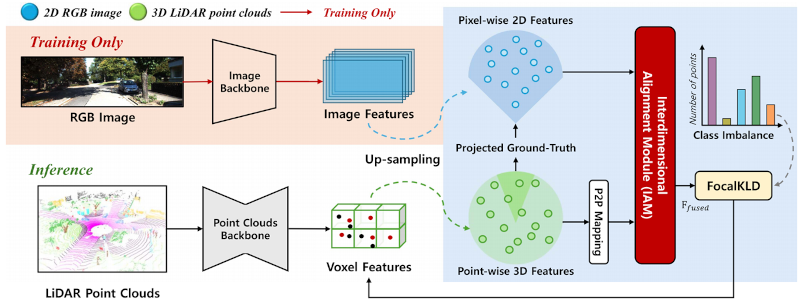
Abstract
3D semantic segmentation is a task to classify a set of 3D points in a scene into semantically meaningful objects. Most existing approaches solely rely on single-domain information such as point clouds acquired by LiDAR sensors. However, the amount of information acquired from a single domain information is inher- ently limited. The limitation can be alleviated by complementary knowledge exchange between multi-modal sensors such as RGB and LiDAR sensors, but this leads to increased computational complexity inevitably. To address the problem, we propose a novel Interdimensional Alignment Module (IAM) for knowledge transfer between 2D and 3D information. The proposed IAM aims to exploit multi-modal information during the training by combining com- plementary 2D and 3D information based on knowledge distillation with a teacher-student structure while utilizing single-domain in- formation during the inference stage to keep the computational cost low. Specifically, the teacher network utilizes 3D point clouds projected onto the paired 2D image to extract geometrically aligned key-value pairs from each modality. After that, the extracted global context vectors are exchanged between modalities to generate cross-modal attention-based 2D–3D fused features. The prediction from the fused features is adopted as unidirectional guidance to the lightweight student network, therefore, only 3D information is required for the inference. We also design a FocalKLD loss to effectively deal with the class imbalance problem during the distil- lation. This leads to significantly improved performance compared to previous single-domain segmentation methods. Experimental results on SemanticKITTI and nuScenes datasets show that our model is effective and superior to previous methods.